


Disaster Recovery
Wstęp, czyli o czym tym razem będziemy dywagować. . .
Disaster Recovery to zbiór procedur oraz strategii związanych z reagowaniem firmy na nieoczekiwane zdarzenia – katastrofy, mające ogromny wpływ na funkcjonowanie tej firmy. Zastanowimy się jakie są możliwości zabezpieczenia się przed skutkami takich katastrof.
Wyższy poziom wtajemniczenia, czyli Disaster Recovery. . .
W poprzednim odcinku sagi rozważaliśmy metody zabezpieczenia naszego środowiska informatycznego przed niespodziankami w postaci awarii poszczególnych elementów naszej infrastruktury. Zabezpieczeniami obejmowaliśmy pamięć masową, serwery, czy wręcz ich zasilanie. Działania te miały jeden cel – aby zaistniałe awarie w jak najmniejszym stopniu wpłynęły na dostępność naszych usług czy aplikacji, które to w sposób pośredni lub bezpośredni przyczyniają się do ilości pieniędzy jakie zarabia lub traci nasza firma. Zabezpieczenia te sprawdzają się rewelacyjnie w przypadku standardowych i możliwych do przewidzenia problemów obejmujących pojedyncze elementy naszej infrastruktury. Awarie pojedynczych dysków, serwerów czy kart PCI od tej pory staną się chlebem powszednim naszych administratorów, ale nie naszego biznesu. Taka sielanka może, ale nie musi trwać zbyt długo, przerwać ja może zdarzenie zwane katastrofa – Disaster.
BCP, czyli co zrobić aby firma przetrwała. . .
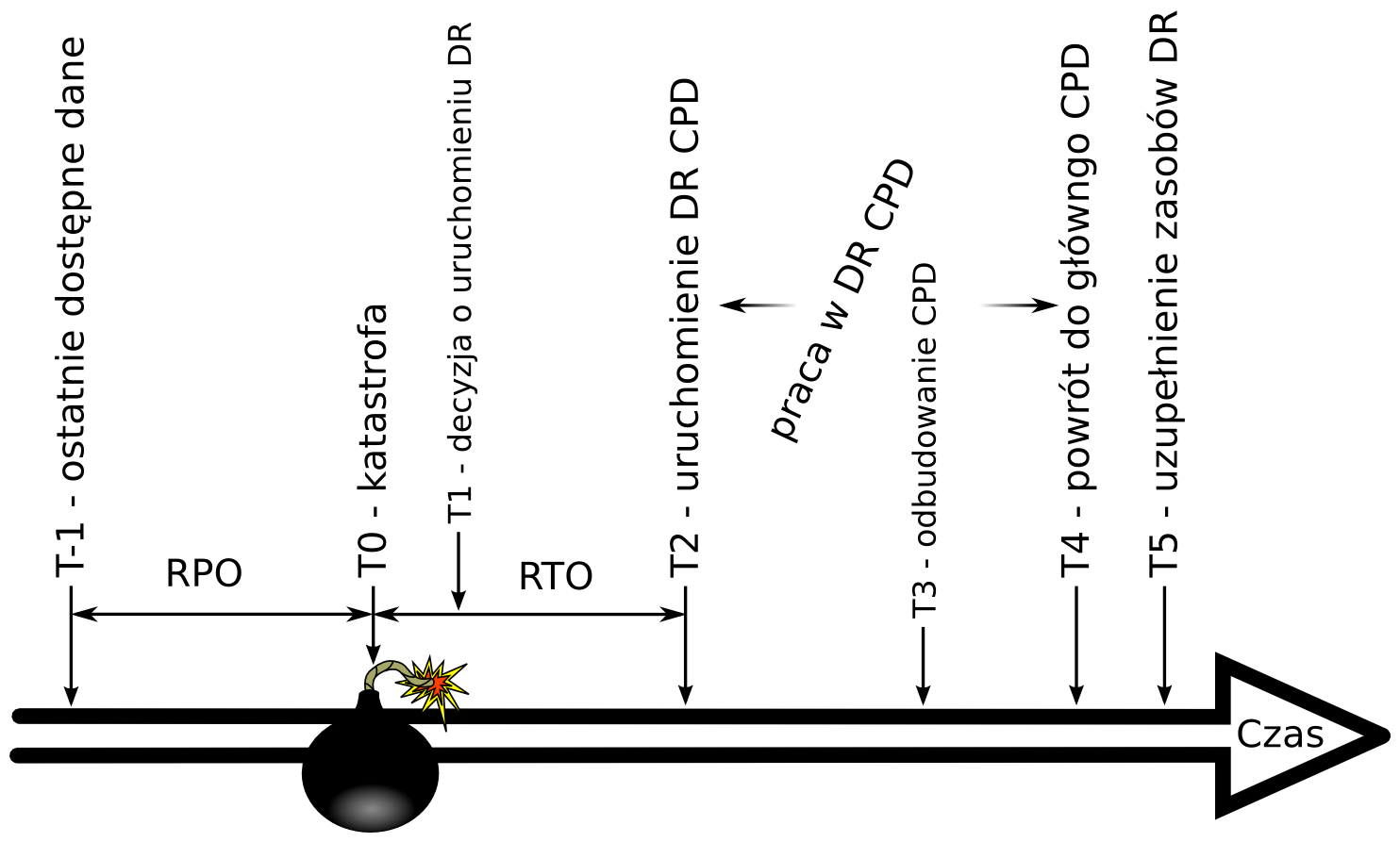
Katastrofa, czyli zdarzenie niespodziewane o ogromnym, negatywnym wpływie na działalność firmy może się przytrafić każdemu. Z definicji katastrofie nie możemy zapobiec, co nie oznacza, że nie powinniśmy minimalizować prawdopodobieństwa wystąpienia niektórych rodzajów katastrof poprzez odpowiedni dobór lokalizacji, projektu, materiałów czy zabezpieczeń naszego centrum przetwarzania danych. Oczywiście, nie każda katastrofa będzie tak samo problematyczna dla firmy więc powinniśmy zajmować się wyłącznie tymi, których wystąpienie może potencjalnie doprowadzić do upadku firmy i zamknięcia biznesu z powodu wygenerowania strat, których firma nie będzie mogla zaakceptować (a może raczej jej właściciele czy wierzyciele). Dlatego na początku zajmiemy się BCP (ang. Business Continuity Plan), czyli Plan Zapewniania/ Kontynuacji Biznesu. Czym jest BCP? To strategia przetrwania firmy w wypadku dotknięcia jej dowolnym rodzajem katastrofy zagrażającej dalszemu funkcjonowaniu. Na strategie tę składa się zbiór planów, procedur, w tym schematów komunikacji i podejmowania decyzji, dotyczących różnych obszarów działalności firmy, podziałów funkcjonalnych czy geograficznych. BCP zawiera także dogłębna analizę kluczowych usług firmy, które muszą być przez firmę utrzymywane lub świadczone bez względu na okoliczności (np. wymogi prawne). Brak utrzymywania lub świadczenia tych usług oznacza w krótkim czasie upadek firmy. Dotychczasowa metodologia i praktyka podpowiada, aby przygotowywać oddzielne BCP na wypadek wystąpienia różnych rodzajów, różnych w skutkach czy zasięgu katastrof. Tak więc powstawały bardzo szczegółowe plany na wypadek: powodzi, trzęsienia ziemi, pożaru, tornado, katastrofy budowlanej, zamieszek itp., itd. Oczywiście większość z nich była mocno do siebie podobna, w końcu co za różnica czy budynek się zawali czy spłonie. Na szczęście ostatnio odchodzi się od nic nie wnoszącej różnorodności i drobiazgowości takich planów BCP na rzecz jednego ogólnego planu obejmującego scenariusz katastrofy nieprzewidywalnej o dowolnie małym prawdopodobieństwie zaistnienia. Dzięki takiemu podejściu upraszcza się bardzo wiele rzeczy, a wszelkie wysiłki skupiają się na zabezpieczeniu usług krytycznych, a nie przeciwdziałaniu poszczególnym rodzajom katastrof. Pierwszym etapem tworzenia BCP jest określenie usług krytycznych dla funkcjonowania firmy – na tym etapie specjaliści z działów IT praktycznie nie maja nic do roboty (chyba że firma to prawie 100% IT). Wtedy okazuje się, że dotychczasowe pojmowanie przez działy IT krytyczności usług w firmie zazwyczaj różni się od tego co faktycznie jest krytyczne. Dla każdej z usług krytycznych strona biznesowa zmuszona jest określić dwa najważniejsze (także dla IT) parametry funkcjonalne: RTO (ang. Recovery Time Objective) oraz RPO (ang. Recovery Point Objective). Parametr RTO określa maksymalny akceptowalny czas od wystąpienia katastrofy po którym usługa musi zostać uruchomiona. W przypadku parametru RPO określamy możliwe do zaakceptowania straty danych spowodowane katastrofą. Już na wstępie mamy trzy źródła strat spowodowanych przez katastrofę: zniszczenia mienia, zniszczenia danych oraz przerwa w świadczeniu usług. Jeśli mamy już listę usług krytycznych wraz z ich parametrami, to w następnym kroku powinniśmy zastanowić się jakie są możliwe sposoby realizacji usługi krytycznej. Zapasowy sprzęt?, a może tylko zmiana procedur czy przejście na obsługę ręczną? W końcu nie wszystkie plany muszą od razu zakładać ponowne zbudowanie działu IT.
DR, czyli jak to się robi w informatyce. . .
Jeśli jednak w naszej firmie istnieją usługi krytyczne, które muszą być realizowane przez dział IT, to nie pozostaje nam nic innego jak dokładniej przeanalizować informacje jakie zostały zebrane w BCP i na ich podstawie dostosować wymagania projektu DR. Ale czym się właściwie różni BCP od DR? DR jest zwyczajnie elementem BCP obejmującym procedury i mechanizmy związane z realizacja BCP i bezpośrednio z niego wynikające. DR to realizacja strategii BCP, to materiał roboczy w trakcie katastrofy. Aby dokładniej zrozumieć, co powinno składać się na poprawnie zaprojektowane środowisko DR, przeanalizujmy poszczególne etapy przykładowej katastrofy. DR rozpoczyna się od decyzji Sztabu Kryzysowego o uruchomieniu poszczególnych procedur. Następnie w czasie RTO poszczególne usługi krytyczne zostają uruchomione w lokalizacji zapasowej (która będzie opisana za chwilę) – jest to pierwszy etap realizacji procedur DR. W momencie zakończenia uruchamiania ostatniej usługi krytycznej środowisko IT przechodzi w awaryjny tryb pracy w lokalizacji zapasowej – jest to drugi etap DR. Taki stan utrzymywany jest do czasu odtworzenia głównego centrum przetwarzania danych (wybudowanie CPD, czy zakup sprzętu), po którym następuje przełączenie usług do lokalizacji podstawowej – trzeci i równie ważny etap DR. Na zakończenie lokalizacja zapasowa jest ponownie przygotowywana do stanu wyjściowego i gotowości na przejecie pracy – czwarty i ostatni etap. Tak więc procedury DR nie kończą się na samym przełączeniu usług. Procedury te muszą zapewnić możliwość normalnej pracy operacyjnej w lokalizacji zapasowej i, co jest równie ważne, powrót z przetwarzaniem do lokalizacji głównej. W procedurach DR musimy pamiętać także o schemacie komunikacji, decyzyjności (w szczególności w punktach związanych z wyzwalaczami działań) czy wymaganych zasobach krytycznych.
Ośrodek zapasowy
Przystosowując systemy informatyczne do świadczenia usług wysoko-dostępnych, postępowaliśmy zgodnie z zasadą eliminacji SPOF począwszy od poziomu okablowania sieciowego czy zasilania, a skończywszy na klastrach i farmach serwerów. Kolejnym krokiem w eliminacji SPOF jest zduplikowanie centrum przetwarzania danych, na początku jako środowiska serwerowni. Założenie jest następujące: dana firma posiada główne centrum przetwarzania danych (w szczególności takich centrów może być kilka), w którym znajdują się wszystkie krytyczne usługi wyszczególnione w BCP. W przypadku kiedy główne centrum przetwarzania danych z dowolnego powodu nie będzie mogło świadczyć usług, to wszystkie usługi krytyczne zostaną uruchomione w zapasowym centrum przetwarzania. Dlaczego w zapasowym centrum przetwarzania danych uruchamiane są wyłącznie usługi krytyczne? Wyłącznie ze względów finansowych. Doświadczenie wielu firm pokazuje, że koszt uruchomienia usług niekrytycznych w lokalizacji zapasowej zazwyczaj przewyższa straty spowodowane niedziałaniem tych usług. Jakie są cechy charakterystyczne zapasowego centrum przetwarzania? Po pierwsze musi ono znajdować się w pewnej odległości od głównej serwerowni, takiej aby zdarzające się na danym obszarze kataklizmy i katastrofy (powodzie, pożary, itp.) mogły objąć swoim zasięgiem co najwyżej jedną z istniejących serwerowni. Oczywiście panuje tu zasada, że im bardziej ośrodki są oddalone od siebie, tym większe bezpieczeństwo zapewniają. Stad wniosek, że najbezpieczniejszy ośrodek ulokowany będzie na przeciwnej półkuli ziemskiej. Niestety wraz ze wzrostem odległości pomiędzy ośrodkami wzrastają także koszty utrzymania takiego ośrodka oraz możliwy do osiągnięcia parametr RPO usług krytycznych zabezpieczanych przez ten ośrodek. Dodatkowo w przypadku ograniczonej ilości administratorów i specjalistów jakimi dysponuje (lub może dysponować) firma zwiększenie odległości pomiędzy ośrodkami może mieć negatywny wpływ na możliwy do osiągnięcia parametr RTO dla usług krytycznych, w przypadku kiedy administratorzy będą musieli dojechać do ośrodka zapasowego. Kolejnym parametrem jest wielkość ośrodka. Z jednej strony ośrodek powinien być wystarczająco duży, aby pomieścić wymaganą ilość serwerów i infrastruktury dodatkowej oraz, o ile wymagają tego procedury DR, posiadać stosowną powierzchnię biurową dla administratorów. Z drugiej strony koszt utrzymania takiego ośrodka jest zależny od jego wielkości. Nasz ośrodek zapasowy może pracować w trybie on-line, gotowy niezwłocznie podjąć pracę lub w trybie off-line, gdzie gotowość operacyjną osiągnie po uruchomieniu zasilania oraz serwerów. Jak można się domyślić pierwszy tryb pracy jest znacznie droższy, za to w znaczący sposób może wpłynąć na możliwy do osiągnięcia czas RTO dla usług krytycznych. Ostatnim z najważniejszych parametrów ośrodka zapasowego jest poziom zabezpieczenia środowiska serwerowni, w szczególności zasilania.
Strategie
Ośrodek zapasowy sam w sobie jest dodatkowym zabezpieczeniem już zabezpieczonych przed awarią systemów informatycznych. Z tego powodu rozbudowanie dodatkowych zabezpieczeń takich jak podwojone obwody zasilania, UPS’y czy generatory prądu, w samym ośrodku zapasowym oznacza podniesienie kosztów całego przedsięwzięcia. W szczególności, że wydawane w ten sposób pieniądze w żadnym możliwym do określenia czasie nie przyniosą zwrotu z inwestycji, co więcej, w założeniach najlepiej by było aby ośrodek ten nigdy nie musiał udowadniać swojej przydatności. Z logicznego czy biznesowego punktu widzenia, każde wydane na DR pieniądze są bezpowrotnie stracone. Sytuacja wyjaśnia się dopiero wtedy, kiedy biznes zacznie traktować ten wydatek jako inna formę wykupienia ubezpieczenia która zamiast w dalszym czasie pokryć zaistniałe straty zwyczajnie do nich nie dopuszcza. Zmuszeni jesteśmy do połączenia ze sobą kilku skrajnych wymagań: parametrów RTO + RPO, lokalizacji zapasowej oraz dostępnego budżetu i technologii (o ograniczeniach fizyki nie wspominając). W praktyce co najmniej jedno z wymagań będzie całkowicie sprzeczne czy niemożliwe do spełnienia z pozostałymi. W takim wypadku zmuszeni będziemy do modyfikacji naszych wymagań i określenia nowej strategii BCP czy DR. Z praktyki powiem, że najłatwiej zmienia się parametry RTO czy RPO, a najtrudniej wielkość przydzielonego budżetu. Na szczęście dostępna technologia jest z roku na rok coraz lepsza.
Kopie zapasowe - Backupy
Uniwersalna receptura związana z uruchamianiem środowiska informatycznego po katastrofie wygląda następująco: „Po pierwsze musisz mieć dane. (...)” Tworzenie kopii zapasowych jest podstawowym mechanizmem zabezpieczenia danych przed utratą. Mechanizm ten polega na cyklicznym wykonywaniu kopii danych na oddzielne nośniki i przechowywaniu ich przez czas określony polityką backupową. W wyniku stosowania poprawnej polityki backupowej, otrzymujemy zestaw kopii danych z różnych momentów w czasie. Najczęściej wykorzystywanymi nośnikami do tego celu są taśmy, dyski twarde lub płyty CD/DVD. Każdy z nich ma swoje zalety i wady. Płyty CD/DVD oraz taśmy jeszcze do niedawna były najtańszymi nośnikami danych. Obecnie coraz częściej dyski twarde są tańsze. Podstawowa zaleta dysków, czyli relatywnie niskie opóźnienia w losowym dostępie do danych umożliwiają efektywną realizację szybkich backupów jak i szybkiego odtwarzania danych. Taśmy i płyty, w przeciwieństwie do dysków twardych są mobilne i można je bezproblemowo transportować do innych lokalizacji. Ze względów wydajnościowych, system wykonywania kopii zapasowych zazwyczaj zlokalizowany jest w tej samej lokalizacji, co środowiska produkcyjne. Z oczywistych względów, nie jest to dobre rozwiązanie i w przypadku zaistnienia katastrofy trzeba zakładać, że wszystko co znajdowało się w podstawowej lokalizacji uległo zniszczeniu lub nie jest dostępne. Określiliśmy więc pierwsze wymaganie przy realizacjach kopii zapasowych na potrzeby DR muszą być składowane w lokalizacji zapasowej. To wymaganie może być zrealizowane na wiele sposobów. Najprostszym jest zebranie nośników ostatnio wykonanych kopii zapasowych i przetransportowanie ich do zdalnej lokalizacji. Taka metoda ma swoje wady, gdyż w przypadku zaistnienia potrzeby operacyjnego odzyskania danych, nośniki te muszą być spowrotem przetransportowane do lokalizacji głównej co znacznie wydłuża czas ich odzyskania. Kolejną metodą jest lokalne klonowanie taśm. W tym przypadku, w okresach bezczynności lub małej aktywności systemu backupowego, ostatnio wykonane kopie zapasowe są nagrywane na dedykowane nośniki (klonowane), a następnie nośniki te są transportowane do lokalizacji zapasowej. Metoda ta także posiada wady, gdyż pomiędzy wykonaniem kopii zapasowej, a jej zabezpieczeniem w zdalnej lokalizacji mija wiele godzin które należy dodać do parametru RPO w dotychczasowych metodach. Czas ten można skrócić poprzez dodatkowe modyfikacje metody klonowania. Na początek klonowanie będziemy realizować w tym samym czasie, co wykonywanie podstawowej kopii bezpieczeństwa – będzie to więc mirroring taśm. Dzięki temu, już po wykonaniu backupu taśmy gotowe są do wywiezienia do zdalnej lokalizacji. Jeśli teraz dodamy do tego odpowiednio szybkie łącze pomiędzy lokalizacjami, to mirroring taśm możemy realizować od razu w zdalnej lokalizacji, co oczywiście kosztuje. Pozostaje nam jeszcze do przeanalizowania ostatnia właściwość wykonywania kopii zapasowych, czyli optymalizacja ze względu na czas wykonywania kopii albo odtwarzania danych. Problem ten ujawnia się gównie w przypadku taśm i płyt, gdzie największą wydajność uzyskuje się w strumieniowym zapisywaniu lub odczytywaniu danych, a jakiekolwiek fluktuacje w strumieniu powodują znaczny spadek wydajności. Aby uzyskać dużą wydajność zapisu na taśmy stosuje się przeplot strumienia danych, dzięki temu wiele relatywnie wolnych lub niestabilnych wydajnościowo klientów łączonych jest w jeden strumień danych. Niestety taka strategia zapisu oznacza, że podczas odtwarzania danych jednego z klientów taśma musi być co jakiś czas przewijana lub odczytywany jest pełny strumień danych. Jeśli odczytujemy pełny strumień danych to tylko część z tych danych jest faktycznie odtwarzanymi danymi. W przypadku DR oznacza to wydłużenie czasu RTO. Jedynym możliwym rozwiązaniem jest Disaster Recovery 75 reorganizacja danych zapisywanych na taśmach. Można tego dokonać na dwa sposoby: w trakcie klonowania taśm lub z zastosowaniem mechanizmu buforowania danych na dyskach twardych, tzw. spool dyskowy. Buforowanie danych backupowych na dyskach ma także tę zaletę, że umożliwia natychmiastowe skorzystanie z tych danych w przypadku odtwarzania, bez kolizji z innymi zadaniami korzystającymi z danej taśmy. Nie występuje tutaj także problem rywalizacji dostępu do napędów w bibliotekach taśmowych czy płytowych. W skrajnym wypadku możemy pokusić się o jednorodne środowisko realizacji kopii zapasowych z wykorzystaniem dysków zarówno po stronie lokalizacji podstawowej jak i zapasowej połączonych wystarczająco wydajnym łączem. Uzyskamy w ten sposób najmniejsze możliwe czasy RTO oraz RPO dla metody zabezpieczenia danych przy pomocy kopii zapasowych.
Replikacja
Dalsze poprawianie czasów RTO oraz RPO wymaga zastosowania innej metody zabezpieczania i aktualizacji danych po stronie zapasowego centrum przetwarzania. Rozwiązaniem tym jest replikacja danych. Replikacja polega na ciągłym synchronicznym lub asynchronicznym kopiowaniu zapisywanych danych z lokalizacji podstawowej poprzez wystarczająco wydajne łącze do lokalizacji zapasowej na odpowiednio przygotowane środowisko pamięci masowej. W przypadku replikacji synchronicznej każda operacja zapisu na dyski/macierz dyskową zostanie potwierdzona dopiero w przypadku, kiedy operacja ta zostanie poprawnie zapisana w lokalizacji zapasowej.
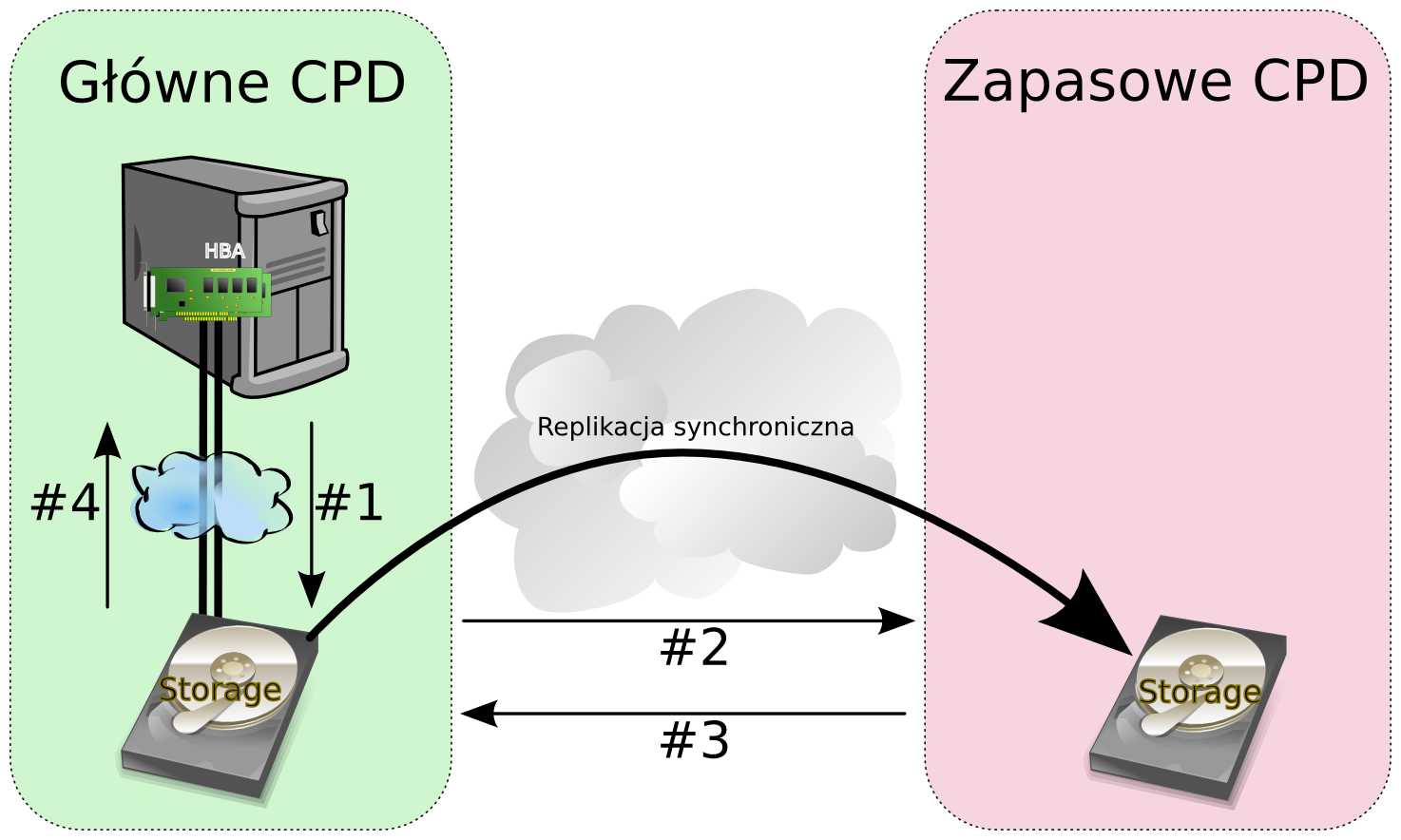
Taka praca oznacza dodanie do czasu trwania każdej operacji zapisu dodatkowego opóźnienia na które składają się: czas przesyłania danych po łączu, operacja zapisu danych na dyskach w lokalizacji zapasowej oraz czas powrotu potwierdzenia wykonania operacji z powrotem po łączu. Oczywiste jest w takim wypadku, że otrzymany czas obsługi operacji zapisu może zostać wydłużony nawet kilkukrotnie, co w przypadku systemów często zapisujących dane może oznaczać nawet kilkukrotny spadek wydajności do poziomu nieakceptowalnego przez biznes. Dzięki takiej właściwości replikacji synchronicznej uzyskujemy czasy RPO praktycznie równe zero, ponieważ w dowolnym momencie czasowym dane w lokalizacjach różnią się co najwyżej o jedną niepotwierdzoną operację zapisu. Dla systemów transakcyjnych oznacza to dokładność do ostatniej potwierdzonej transakcji – transakcje niepotwierdzone w przypadku awarii zostaną zwyczajnie wycofane. Oczywiście w przypadku awarii łącza po którym realizowana jest replikacja operacje zapisu są całkowicie wstrzymane. Z drugiej strony w replikacji asynchronicznej otrzymujemy potwierdzenie operacji zapisu, niezwłocznie po tym jak operacja ta zostanie zapisana w lokalnym buforze wyjściowym. Bufor ten następnie jest cyklicznie wysyłany do lokalizacji zdalnej i czyszczony po otrzymaniu potwierdzenia zapisu. Inną stosowaną strategią replikacji asynchronicznej jest uaktualnianie mapy bloków zmodyfikowanych, i na tej podstawie cykliczne przesyłanie tych bloków do lokalizacji zdalnej. W pierwszej strategii zapewnioną mamy kolejność modyfikacji danych, co jest szczególnie ważne w przypadku systemów transakcyjnych. Dodatkowo minimalizujemy wpływ dostępności łącza replikacyjnego w ramach odpowiednio dużego bufora wyjściowego, w drugim wypadku praktycznie uniezależniamy się od potencjalnych problemów z łączem i kłopotami z replikacja na dowolnie długi czas. W skrajnym wypadku będziemy musieli zareplikować 100% danych.
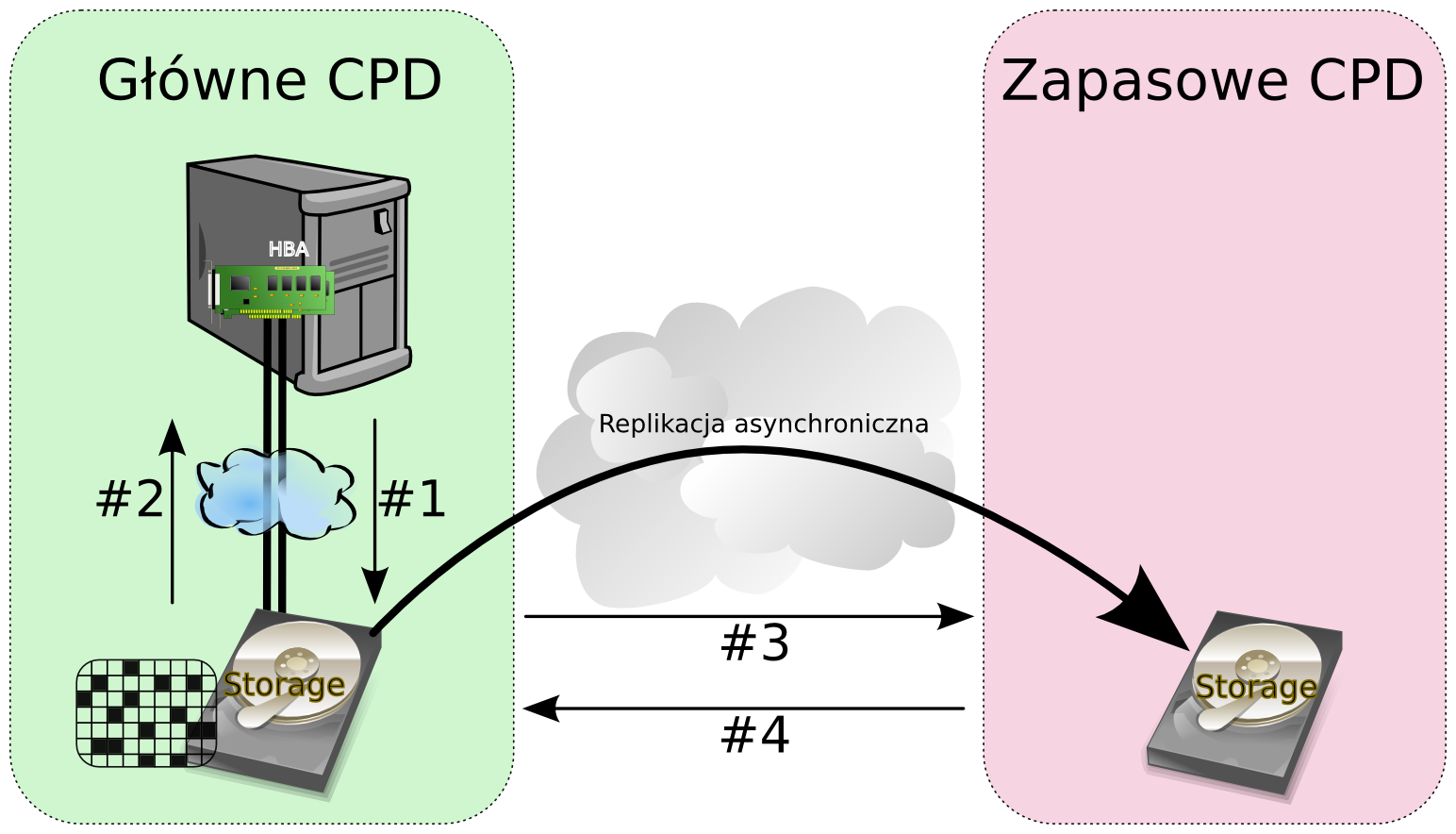
Zarówno replikację synchroniczną jak i asynchroniczną realizować możemy na różnych warstwach infrastruktury. Najprostsza w implementacji i najbardziej uniwersalna jest replikacja realizowana przez oprogramowanie macierzy dyskowej. W ten sposób jesteśmy w stanie objąć replikacją dowolny system informatyczny, o ile całość wymaganych danych umiejscowiona jest na macierzy. Zazwyczaj dodatkowymi wymaganiami dla realizacji takiej replikacji jest wykorzystanie takich samych macierzy (albo co najmniej tego samego producenta) zarówno w lokalizacji głównej jak i zapasowej czy replikacja za pomocą dedykowanych łączy lub protokołu FC zamiast TCP/IP. Innym w miarę uniwersalnym i praktycznym rozwiązaniem jest replikacja realizowana poprzez mechanizmy wbudowane w warstwę zarządzania przestrzenią dyskową systemu operacyjnego. W takim wypadku zazwyczaj możemy korzystać z dowolnych macierzy, czy wręcz dysków lokalnych serwera po stronie ośrodka głównego jak i zapasowego. Bez problemu możemy korzystać z sieci TCP/IP, więc rozwiązanie takie często jest tańsze niż z wykorzystaniem odpowiednich macierzy. Ostatecznie replikowanie danych może odbywać się na poziomie aplikacyjnym. Zarówno bazy danych (spora ich część), usługi katalogowe czy aplikacje specjalistyczne maja takie udogodnienia, ale rozwiązania te są ograniczone do konkretnych aplikacji i może okazać się że nie obejmują one w pełni systemów które powinny być objęte replikacją przez co zmuszeni będziemy do wdrożenia dodatkowych rozwiązań uniwersalnych. W tym momencie problemem może stać się wielość rozwiązań replikacyjnych jakie będziemy stosować w naszym środowisku zamiast jednego uniwersalnego. Wykorzystanie replikacji zamiast kopii zapasowych dodatkowo zmniejsza możliwy do uzyskania czas RTO związany z brakiem odtwarzania danych z kopii zapasowych, ponieważ dane są już gotowe na dyskach. Łącząc to z praktycznym do uzyskania parametrem RPO równym zero, rozwiązania takie stosowane są wyłącznie dla najbardziej krytycznych środowisk firmy.
Infrastruktura zapasowa
Teraz możemy opisać dalszy ciąg receptury: Po pierwsze musisz mieć dane. Aby z nich skorzystać musisz je mieć dostępne na dyskach czyli możesz potrzebować odtworzenia ich z kopii zapasowych. Następnie musisz mieć serwery na których uruchomisz przetwarzanie swoich danych. Serwery powinny być wcześniej przygotowane do uruchomienia przetwarzania. Umożliwi to minimalizacje parametru RTO usług krytycznych. Wymóg wcześniejszego przygotowania serwerów wynika zazwyczaj z różnic w konfiguracji infrastruktury w centrum zapasowym. Co najmniej inna adresacja sieci, inna logika sieci czy wręcz całkowicie odmienne modele serwerów czy dostępnych usług. W takim wypadku środowisko serwerowe na potrzeby DR budowane jest zazwyczaj z dedykowanych do tego celu maszyn. Niestety bardzo często DR wypełniane jest serwerami wycofywanymi ze środowiska produkcyjnego. Wynika to z chęci szefostwa do minimalizacji kosztów budowy DR. Rozwiązaniem tej kwestii kosztów może być podpisanie z dostawcami sprzętu odpowiednich umów w których dostawcy zobowiązują się dostarczyć sprzęt w określonym czasie. Czas ten dopisujemy do parametru RTO. Inną ciekawą propozycją jest wykorzystanie sprzętu przeznaczonego na środowiska testowe, dzięki czemu sprzęt taki będzie normalnie wspierał działalność operacyjną firmy optymalizując koszty poniesione na realizację DR. Budując infrastrukturę zapasową musimy pamiętać, że zgodnie z planami BCP gówna działalność operacyjna będzie przez jakiś czas realizowana całkowicie na infrastrukturze zapasowej. Zastanówmy się jak długi może być to czas. W skrajnym przypadku po zaistnieniu katastrofy firma będzie musiała ponownie wybudować główne centrum przetwarzania, zakupić wymagany sprzęt, dokonać instalacji oraz konfiguracji środowiska, a do tego przez cały ten okres będzie musiało być zapewnione finansowanie inwestycji oraz bieżącej działalności operacyjnej. Zazwyczaj okres ten mierzony jest w miesiącach, a może nawet w latach. To oznacza że przez cały ten czas środowisko zapasowe będzie narażone na standardowe awarie elementów infrastruktury. Z tego powodu zalecane jest, aby infrastruktura zapasowa została zbudowana lub w bardzo krótkim czasie rozbudowana o wszystkie mechanizmy redundancji jakie są stosowane w obecnych środowiskach produkcyjnych. Oznacza to zadbanie o redundancję dysków, sieci, zasilania, kart PCI, czy może nawet serwerów i budowę pełnych środowisk klastrowych.
Powrót i utrzymanie gotowości
Bardzo często firmy w swoich planach DR skupiają się wyłącznie na jednym, czasami na dwóch z czterech etapów procedur DR. Praktycznie całkowicie zapomina się o tym, że praca w trybie awaryjnym się zakończy i trzeba będzie powrócić z przetwarzaniem do głównego centrum obliczeniowego. Ten etap jest bardzo podobny do etapu pierwszego – uruchomienia przetwarzania w lokalizacji zapasowej, ale powinien być łatwiejszy do realizacji ze względu na znacznie mniejszą presję czasową, oraz możliwe wcześniejsze zaplanowanie działań powrotnych. Nie oznacza to, że etap powrotu należy całkowicie pominąć. Tak samo jak w pierwszym etapie, musimy zapewnić aktualność danych (replikacja lub backup), najlepiej z RPO równym zero, wymagane rekonfiguracje infrastruktury oraz testy po przełączeniu, a wszystko to w analogicznym czasie RTO. Jeśli już udało nam się przebaczyć całość usług krytycznych ponownie do głównego centrum obliczeniowego to pozostaje nam ostatni etap realizacji procedur DR - czyli przywrócenie gotowości lokalizacji zapasowej. Tak samo jak po każdej genialnej imprezie przychodzi czas na sprzątanie i uzupełnianie zapasów trunków czy jedzenia przed wydaniem kolejnej imprezy – tak samo nasza lokalizacja zapasowa, a co najważniejsze jej zasoby muszą być uzupełnione. Koło się zamyka i ponownie jak w trakcie wdrażania projektu DR, trzeba zweryfikować listę zasobów krytycznych, uzupełnić braki, ponownie skonfigurować środowiska, zestawić replikację czy uruchomić transport taśm. A jeśli korzystaliśmy ze sprzętu testowego, to także ponowne uruchomienie środowisk testowych – developerzy i testerzy na pewno się do nich stęsknili. W tym momencie przychodzi także czas na refleksje i podsumowania związane z realizacją procedur DR na prawdziwym polu walki. Które elementy w procedurach nie zadziałały, które były poprawne, a z których zwyczajnie nie korzystaliśmy? Podczas uzupełniania zasobów dobrze jest zweryfikować czy w trakcie realizacji procedur pewnych zasobów nie było za mało, a może przesadnie za dużo. Dopiero po zakończeniu tego etapu firma ponownie przygotowana jest na przetrwanie kolejnego ataku katastrofy, w myśl maksymy: „Co cie nie zabije to cie wzmocni...”
Plany i Procedury
Podstawą realizacji działań związanych z DR są szczegółowo spisane procedury postępowania. Procedury powinny dokładnie realizować plany zabezpieczenia każdej z usług krytycznych dla działania firmy. Zazwyczaj wskazane usługi krytyczne nie przekładają się wprost na poszczególne systemy informatyczne i w rzeczywistości tworzą coś na kształt powiązanej ze sobą pajęczyny systemów czy ich fragmentów. W każdym z tych przypadków procedury powinny faktycznie opisywać poszczególne systemy informatyczne, a nie usługi, dzięki czemu unikniemy konfliktów lub braków w procedurach. Poprawnie opisane procedury powinny stanowić zamknięta całość. Jeśli w jakimkolwiek miejscu procedura odwołuje się do zewnętrznych dokumentów muszą one zostać włączone do procedury co najmniej jako załączniki. W każdej z procedur DR muszą się obowiązkowo znaleźć następujące informacje: schemat powiadamiania i raportowania; dokładnie określone wyzwalacze wskazanych kroków procedury; spis zasobów krytycznych wymaganych do realizacji procedury, w tym wspomnianych wcześniej dokumentów zewnętrznych; kolejne kroki procedury opisane w jak najprostszy sposób, aby możliwe było ich wykonanie nawet przez osobę bez wymaganego przeszkolenia; zasady testowania i aktualizacji procedury.
Koszty
Uruchomienie w firmie projektu BCP/DR oznacza poniesienie bardzo dużych kosztów zależnych od rzeczywistych wymagań biznesowych (parametry RTO i RPO). Nie każda firma jest w stanie je ponieść. W takim wypadku należy szukać konsensusu pomiędzy akceptowalnymi parametrami RPO, RTO, a możliwościami finansowymi. Lepiej jest posiadać nie do końca idealne DR ale jakiekolwiek zabezpieczające interesy firmy niż nie posiadać żadnego. Jest to o tyle ważne, że wachlarz możliwości jest duży i w przyszłości po pojawieniu się dodatkowych środków można zastanowić się nad poprawą parametrów zabezpieczenia usług. Jedną z ciekawszych propozycji jest wykorzystanie istniejącej infrastruktury testowej (odpowiednio dostosowanej), dzięki czemu bez zbytniego inwestowania w infrastrukturę zapasową możemy otrzymać w pełni funkcjonalne środowisko DR działające zamiennie ze środowiskiem testowym. Samo wdrożenie środowiska DR oraz stosownych planów nie kończy projektu BCP/DR. Projekt cały czas się toczy – cały czas pojawiają się nowe usługi, które często staja się usługami krytycznymi. Dotychczasowe usługi krytyczne ewoluują lub są wyłączane – to powoduje ciągłą potrzebę aktualizacji istniejących procedur oraz konfiguracji środowiska zapasowego. To wszystko oznacza zwiększone koszty bieżącej pracy operacyjnej. Dodatkowo, aby być pewnym poprawności działań opisanych w procedurach DR oraz tego, że obecna kadra będzie w stanie sprostać wyzwaniom katastrof należy cyklicznie przeprowadzać testy i szkolenia. Najlepiej by było, aby podczas tych testów wykonywać rzeczywiste przyłączenia przetwarzania systemów krytycznych na środowisko zapasowe oraz tak samo weryfikować powrót z przetwarzaniem do lokalizacji głównej. Tylko takie testy dadzą nam pełny obraz naszego przygotowania i bezlitośnie wypunktują niedostatki. Koszty tu, koszty tam, wszędzie czają się koszty. Wydawać by się mogło że projekt BCP/DR to skarbonka bez dna. Wpewnym sensie jest to prawda, z drugiej strony każda forma ubezpieczenia do czasu wypłaty odszkodowania wygląda tak samo.