


High Avaliability
Wstęp, czyli o czym cała rzecz będzie. . .
Wysoka dostępność (ang. High Availability) to zestaw standardów projektowania oraz odpowiedniej implementacji środowiska informatycznego mającego na celu minimalizację czasów nieplanowanych niedostępności czyli przerw w działaniu, braku świadczenia usług. Zastanowimy się jak można realizować takie zabezpieczenia i o czym powinniśmy pamiętać podczas projektowania i implementacji.
Awarie, czyli analogie stosowane. . .
Faktem jest iż każdy wytwór człowieka jest ułomny i prędzej czy później może się zepsuć, czyli przestanie świadczyć swoją podstawową funkcjonalność do której został zaprojektowany i wytworzony.Wświecie informatyki dzielącej się na dwa obozy: sprzętowy (ang. Hardware) oraz oprogramowania (ang. Software) takie problemy także występują. W każdym z tych obozów sposoby reagowania na awarie są odmienne. Jako że praktycznie całość infrastruktury informatycznej ma charakter warstwowy, gdzie każda kolejna warstwa wyższa bazuje na usługach świadczonych przez warstwę niższą to z pełną świadomością możemy mówić o łańcuchu powiązań. Jak już mamy łańcuch powiązań, to powinniśmy pamiętać iż niezawodność łańcucha jest tak duża, jak najbardziej zawodne z jego ogniw. Jeśli jedno z ogniw rozrywa się to całość łańcucha także. W tym miejscu pojawia się pojęcie pojedynczego punktu awarii, czyli po angielsku SPOF – Single Point Of Failure. Podstawową zasadą, którą należy kierować się w trakcie projektowania niezawodnej infrastruktury informatycznej jest niedopuszczenie do powstania SPOF (eliminacja pojedynczych punktów awarii). W naszej analogii jest to wykorzystanie drugiego takiego samego łańcucha do zabezpieczenia się na wypadek pęknięcia jednego z ogniw łańcucha podstawowego. Wykorzystując naszą analogię możemy przeprowadzić od razu analizę takiego podejścia do projektowania od różnych stron: technicznej i finansowej. Pierwsze co się od razu nasuwa to że zastosowanie drugiego łańcucha musi być dwukrotnie droższe. Jest to fakt bezsporny ale na nasze potrzeby uogólnimy go że zwiększenie dostępności/niezawodności zawsze będzie kosztowało dodatkowe pieniądze (czasami większe, czasami mniejsze). Drugim aspektem, tym razem technicznym, jest to że łańcuch zabezpieczający musi być w stanie utrzymać „generowane” obciążenie. W przeciwnym wypadku bardzo szybko sam ulegnie awarii. Stąd mamy kolejny wniosek techniczny, że po wystąpieniu awarii pojedynczego elementu środowisko ponownie posiada SPOF i do czasu naprawienia łańcucha nie posiadamy zabezpieczenia.
Fault-Tolerant, czyli czym HA jest a czym nie. . .
Fault-Tolerant (pol. Odporny na awarie) to zasady projektowania i budowania środowisk bardzo podobne do tych stosowanych w koncepcji Wysokiej Dostępności. Podstawowe różnice pojawiają się w osiąganym celu czyli poziomie niezawodności. Dla środowisk wysoko-dostępnych osiągnięcie celu niezawodnościowego następuje już wówczas kiedy czas RTO (ang. Recovery Time Objective - gwarantowany czas przywrócenia działania usługi) jest znacznie mniejszy od RTO osiąganego dla standardowego niezabezpieczonego środowiska. Zazwyczaj osiągane RTO dla środowisk HA jest rzędu pojedynczych minut albo nawet sekund, a bardzo rzadko dziesiątek minut. Zupełnie inaczej sprawa ma się ze środowiskami FT, gdzie jedyny akceptowany czas RTO jest bliski „0” i praktycznie nieakceptowalny powyżej pojedynczych sekund. Czyli systemy HA dopuszczają pewną niewielką niedostępność usługi, w szczególności jej restartowanie, czy skończony czas podnoszenia usługi po awarii. Dla systemów FT jakakolwiek niedostępność jest praktycznie nieakceptowalna. Dodatkowo tzw. planowane niedostępności związane zazwyczaj z czynnościami administracyjnymi (patchowanie, upgrade sprzętu, itp.) są dla środowisk HA dopuszczalne i nikt nie uwzględnia ich w projektowaniu infrastruktury. Dla systemów FT bardzo często także planowane niedostępności są nieakceptowalne, z tego powodu projektowane są w taki sposób aby wyeliminować także takie działania. Konsekwencją tak przyjętych założeń dla FT i HA jest znacznie większy koszt zaprojektowania oraz implementacji środowisk FT względem HA.
Infrastruktura, czyli dotknięcie sedna sprawy. . .
Jak już zostało to wspomniane infrastruktura informatyczna składa się z warstw. Każda niższa warstwa świadczy usługi dla warstw wyższych. Z tego powodu każdą z warstw możemy rozpatrywać jako osobne przypadki dla których będziemy stosować wszystkie ogólne założenia. Oczywiście takie podejście ma swoje ograniczenia ponieważ każda z warstw musi być odpowiednio „gruba” aby technicznie można było ją objąć tymi zasadami. Dla przykładu serwer z systemem operacyjnym będziemy traktowali jako całą warstwę, aplikację jako kolejną warstwę. Nie ma sensu rozdzielać systemu operacyjnego na warstwy np. warstwa TCP/IP, warstwa VFS czy warstwa zarządzania pamięcią wirtualną bo technicznie jest to całość. Takie podejście ma także i zalety. Podstawową jest to, iż potencjalnie jeszcze bardziej zwiększamy niezawodność całego środowiska ze względu na to iż, że w specyficznych przypadkach (a nie jest ich tak mało) całość środowiska będzie odporna na awarię więcej niż jednego elementu, o ile kolejne awarie pojawią się w innych warstwach infrastruktury.
Pamięć masowa, czyli co w RAIDzie piszczy. . .
Pierwszą warstwą infrastruktury którą się zajmiemy będzie warstwa pamięci masowej. W najprostszym przypadku traktować ją będziemy jako dyski podłączone do jakiegoś kontrolera dyskowego (HBA, ang. Host Bus Adapter) w serwerze. Obecnie nawet w najmniejszych firmach pomiędzy dyskami a kontrolerem HBA pojawia się dodatkowa infrastruktura w postaci sieci SAN (ang. Storage Area Network) oraz macierzy dyskowych podłączanych do tej sieci (będą one opisane dokładniej w kolejnych punktach). W obu przypadkach do rozważenia mamy dwa aspekty: zabezpieczenia danych przechowywanych na dyskach przed utratą oraz niezawodności dostępu do tych danych poprzez dostępne interfejsy. Przed utratą danych podczas awarii dysków można zabezpieczyć się na dwa sposoby: realizując kopie zapasowe lub za pomocą RAIDa. Backup jest fajny ale czas odtworzenia danych może być liczony nawet w godzinach, więc będzie nieakceptowalny, pozostaje nam RAID. RAID (ang. Redundant Array of Independent Disks) czyli „redundantna macierz niezależnych dysków” to termin określający różne schematy rozproszenia danych na kilku niezależnych dyskach w celu osiągnięcia większej wydajności i/lub niezawodności. W historii informatyki doczekaliśmy się wielu sposobów realizacji tej ogólnej idei, lecz w czasach współczesnych najpopularniejszymi i praktycznie stosowanymi są: RAID0, RAID1, RAID5 oraz mieszanka RAID1+0 czy RAID0+1. RAID0 w praktyce nie daje nam dodatkowego zabezpieczenia, wyłącznie zwiększoną wydajność. Zabezpieczenia danych uzyskujemy w RAID1 – zwanym potocznie mirrorem oraz RAID5.
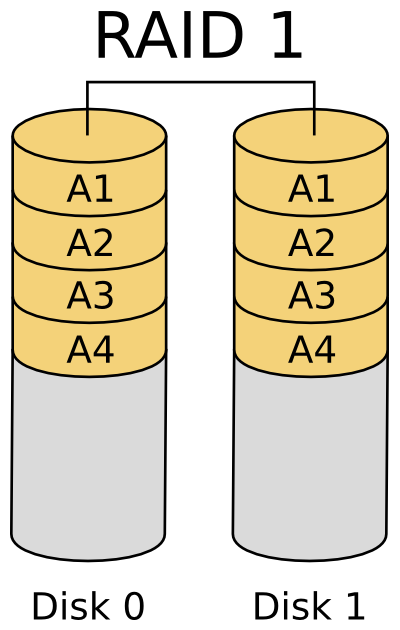 Rysunek 1: Schemat RAID1 Rysunek 1: Schemat RAID1 |
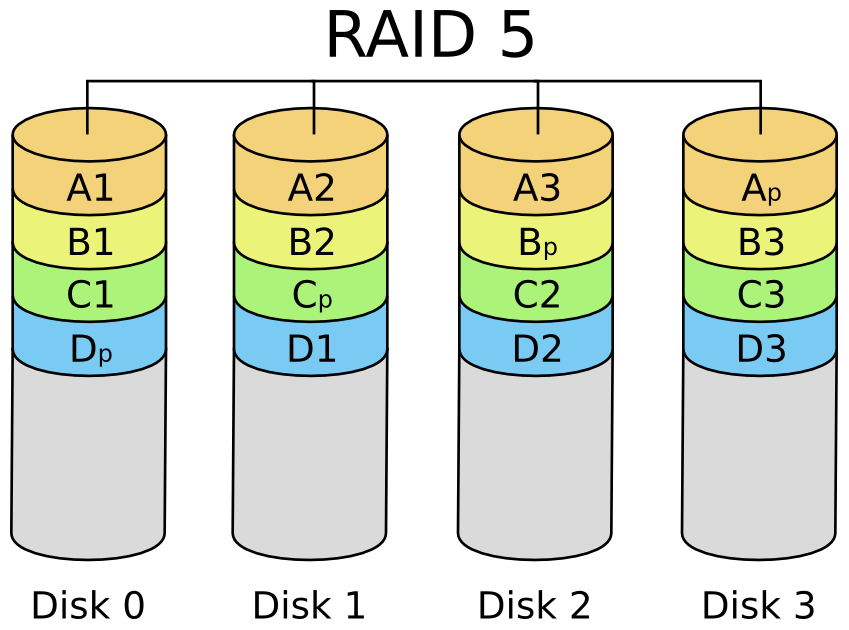 Rysunek 2: Schemat RAID5 Rysunek 2: Schemat RAID5 |
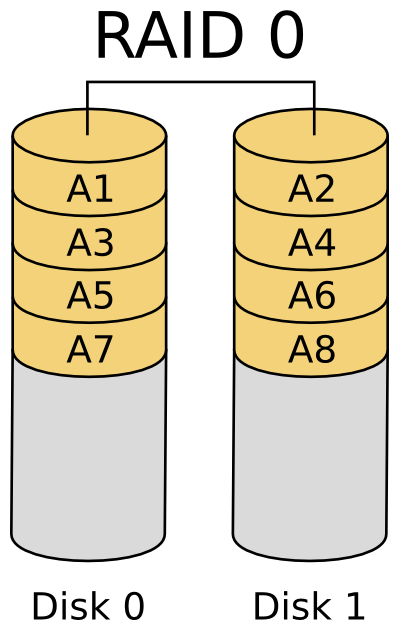 Rysunek 3: Schemat RAID0 Rysunek 3: Schemat RAID0 |
Podstawową różnicą pomiędzy tymi poziomami jest sposób zabezpieczania danych. W RAID1 dane zabezpieczane są poprzez zwyczajne powielanie informacji na różnych dyskach, w przypadku RAID5 dane zabezpieczane są poprzez wyliczanie sum kontrolnych (zazwyczaj XOR) i umieszczanie ich na innym dysku niż dane zabezpieczane. W związku z tym mamy następujące właściwości każdego z RAID’ów (tabela 1):
|
RAID1 (mirror) |
RAID5 |
|---|---|
|
minimum 2 dyski dla stworzenia macierzy RAID |
minimum 3 dyski dla stworzenia macierzy RAID |
|
wymaga co najmniej tyle samo przestrzeni do zabezpieczenia danych co same dane |
wymaga tylko jednego dodatkowego dysku do zabezpieczenia danych |
|
rozwiązane zdecydowanie najdroższe, ale dające najwyższy poziom zabezpieczenia danych i elastyczności, w szczególności w przypadku wykorzystania mirroru z wieloma lustrami |
rozwiązanie dostępne za przystępną cenę, w szczególności że wraz ze zwiększaniem ilości dysków w macierzy procentowy koszt zabezpieczenia danych maleje |
|
|
ograniczona elastyczność i stały poziom zabezpieczenia danych |
|
brak lub niewielki spadek wydajności operacji IO w przypadku awarii |
duży spadek wydajności operacji IO w przypadku awarii związany z potrzebą wyliczania sum kontrolnych danych |
Jak widać powyżej każdy z raidów może znaleźć sobie zwolenników i wymagania które spokojnie spełni. Dla bardziej wymagających RAID1 dla mniej RAID5, czyli zgodnie z zasadą więcej wymagasz, więcej płacisz. Tak więc sprawę ochrony danych mamy zapewnioną, teraz pozostała sprawa kontrolerów HBA i magistrali komunikacyjnych (SCSI, FC, SAS, ATA itp.).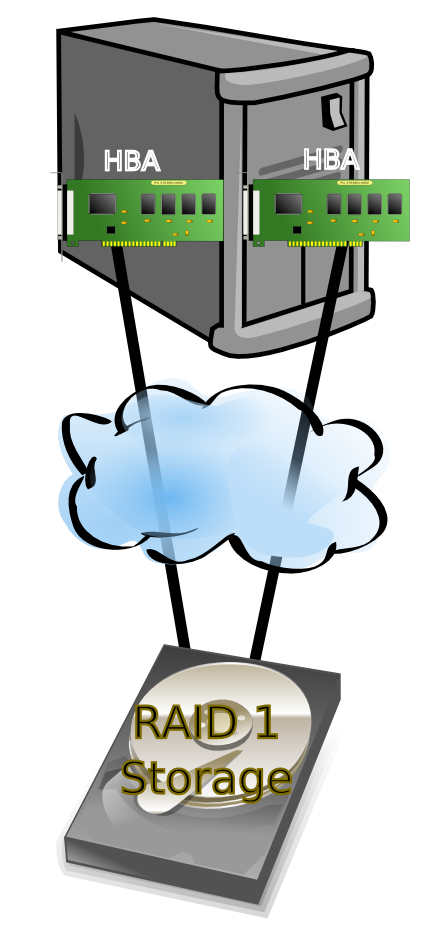 W tym wypadku mamy dwie możliwości: dyski mogą być wystawione/widoczne wyłącznie za pomocą pojedynczego kontrolera (np. ze względów technologicznych – ATA); dyski mogą być widoczne/wystawione jednocześnie na więcej niż jednym kontrolerze HBA – taka sytuacja występuje np. w przypadku FC i sieci SAN. W pierwszym przypadku na łańcuch SPOF składa się cały zestaw: dyski + magistrala + kontroler, z tego powodu jedyną możliwością zabezpieczenia jest zastosowanie dwóch zestawów dysków + magistrala + kontroler i spięcie całości w macierz RAID1 realizowaną na poziomie systemu operacyjnego. Architektura ta mocno ogranicza stosowanie RAID5 ponieważ do każdego z dysków macierzy trzeba by dedykować kontroler HBA, co dodatkowo podraża takie rozwiązanie a w skrajnym przypadku może nie być realizowalne technicznie np. ze względu na brak stosownych slotów PCI w serwerze. W drugim wypadku do zabezpieczenia warstwy HBA należy stosować mechanizmy dostępu wielościeżkowego. Dostęp wielościeżkowy polega na kierowaniu komunikacji do pamięci masowej (dysków) potencjalnie poprzez różne kontrolery HBA. Zazwyczaj dostęp taki realizowany jest za pomocą dwóch trybów pracy: active-standby lub active-active i uzależniony jest od możliwości macierzy dyskowej obsługującej komunikację. W Linuksie będzie to DeviceMapper Multipath, w Solarisie MPxIO, w AIXie MPIO, itd. Dla macierzy RAID5 zabezpieczenie przed awarią kontrolera nie jest trywialne i zazwyczaj odpowiednio zwiększa koszt całości rozwiązania. Praktycznie pozostają nam wyłącznie dwie możliwości: pierwszą jest korzystanie z wydzielonych dla każdego z dysków ale współdzielonych pomiędzy kontrolerami szyn SCSI – sytuację jaką często stosuje się w przypadku budowania klastrów z macierzami współdzielonymi SCSI. Drugą jest korzystanie z dwuportowych dysków FC/SATA/SAS, gdzie powyższą ideę współdzielonego dostępu realizuje się na poziomie elektroniki dysku.
W tym wypadku mamy dwie możliwości: dyski mogą być wystawione/widoczne wyłącznie za pomocą pojedynczego kontrolera (np. ze względów technologicznych – ATA); dyski mogą być widoczne/wystawione jednocześnie na więcej niż jednym kontrolerze HBA – taka sytuacja występuje np. w przypadku FC i sieci SAN. W pierwszym przypadku na łańcuch SPOF składa się cały zestaw: dyski + magistrala + kontroler, z tego powodu jedyną możliwością zabezpieczenia jest zastosowanie dwóch zestawów dysków + magistrala + kontroler i spięcie całości w macierz RAID1 realizowaną na poziomie systemu operacyjnego. Architektura ta mocno ogranicza stosowanie RAID5 ponieważ do każdego z dysków macierzy trzeba by dedykować kontroler HBA, co dodatkowo podraża takie rozwiązanie a w skrajnym przypadku może nie być realizowalne technicznie np. ze względu na brak stosownych slotów PCI w serwerze. W drugim wypadku do zabezpieczenia warstwy HBA należy stosować mechanizmy dostępu wielościeżkowego. Dostęp wielościeżkowy polega na kierowaniu komunikacji do pamięci masowej (dysków) potencjalnie poprzez różne kontrolery HBA. Zazwyczaj dostęp taki realizowany jest za pomocą dwóch trybów pracy: active-standby lub active-active i uzależniony jest od możliwości macierzy dyskowej obsługującej komunikację. W Linuksie będzie to DeviceMapper Multipath, w Solarisie MPxIO, w AIXie MPIO, itd. Dla macierzy RAID5 zabezpieczenie przed awarią kontrolera nie jest trywialne i zazwyczaj odpowiednio zwiększa koszt całości rozwiązania. Praktycznie pozostają nam wyłącznie dwie możliwości: pierwszą jest korzystanie z wydzielonych dla każdego z dysków ale współdzielonych pomiędzy kontrolerami szyn SCSI – sytuację jaką często stosuje się w przypadku budowania klastrów z macierzami współdzielonymi SCSI. Drugą jest korzystanie z dwuportowych dysków FC/SATA/SAS, gdzie powyższą ideę współdzielonego dostępu realizuje się na poziomie elektroniki dysku.
Zasilanie, czyli urządzenia elektryczne najlepiej pracują podłączone do prądu. . .
Zasilanie w obecnych czasach stało się tak powszechne że spora część osób traktuje je jako rzecz zwyczajnie istniejącą, która generalnie jest i nie należy się nią zajmować. Nic bardziej mylnego. Wahnięcia zasilania czy wręcz zaniki mają zgubny skutek w osiąganym poziomie dostępności systemów informatycznych. Także i w tej warstwie należy pamiętać o ogólnych zasadach zwiększania niezawodności lecz bez wsparcia ze strony samej infrastruktury serwerowej czy środowiska serwerowni nie mamy dużego pola do popisu. Podstawowym wymogiem będzie stosowanie serwerów ze zwielokrotnionymi zasilaczami. W tym obszarze mamy dwie możliwości: zasilacze podwojone; zasilacze pracujące w trybie N+1; Pierwsza jest jakby odpowiednikiem dyskowego mirroru, druga jakby raida5, ze wszystkimi zaletami i wadami obu rozwiązań. W przypadku samego środowiska serwerowni ze względów praktycznych stosuje się wyłącznie architekturę z podwojonymi obwodami zasilania. Z tego powodu najbardziej dopasowane będą serwery z podwojonymi zasilaczami. Pojedyncze zasilacze czy zasilacze pracujące w trybie N+1, aby osiągnąć wysoką dostępność, wymagają podłączenia do zasilania poprzez przełączniki napięciowe.
Sieci LAN oraz SAN, czyli jak nie portem go to całym switch’em. . .
Zabezpieczenie sieci LAN oraz sieci SAN odbywa się z wykorzystaniem – i tu niespodzianka – tych samych ogólnych zasad projektowania systemów wysoko-dostępnych. Jedyna różnica jest taka, że jak do tej pory dopracowano się wyłącznie jednego kierunku projektowania – duplikacji. Tak więc jeśli mamy na myśli zwiększenie niezawodności sieci to jedyna odpowiedź to zduplikowanie infrastruktury. 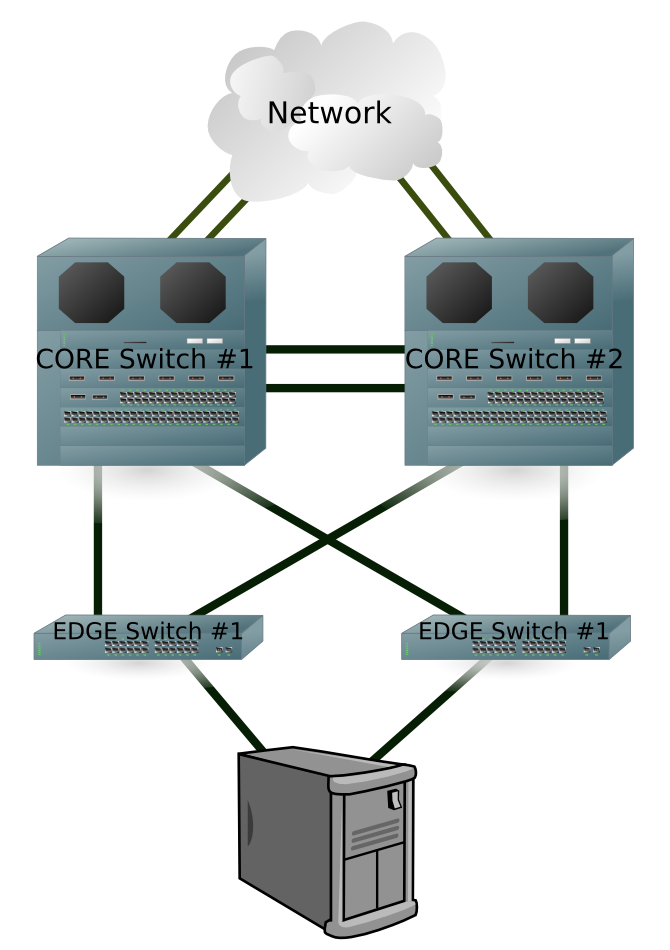 Na szczęście urządzenia sieciowe LAN czy nawet SAN stają się coraz powszechniejsze, i przez to coraz tańsze, dzięki temu zastosowanie duplikacji infrastruktury nie jest już tak bolesne finansowo jak to kiedyś bywało. Najpopularniejszą obecnie architekturą sieci jest tzw. Core-Edge. Oznacza to budowanie sieci w oparciu o zaawansowane i wydajne główne przełączniki sieciowe, realizujące kierowanie i agregację ruchu z podłączonych sieci. Do nich przyłączone są przełączniki brzegowe do których podłączane są zazwyczaj urządzenia końcowe - serwery, albo połączenia do innych, odległych sieci. Architektura taka tworzy zazwyczaj sieć w postaci drzewa o pojedynczych poziomach odgałęzień. Jak do tej pory opis ten miał zastosowanie zarówno dla sieci LAN jaki i SAN i na tym podobieństwa projektowe tych sieci się kończą. W przypadku sieci LAN duplikacja oznacza dodanie do każdego z poziomów drzewa bliźniaczego urządzenia obsługującego potencjalnie taki sam ruch jak urządzenie zabezpieczane. Każde z tych urządzeń należy odpowiednio podpiąć do pozostałych urządzeń zgodnie z następującym schematem: każde z urządzeń końcowych musi być podłączone do dwóch różnych przełączników brzegowych obsługujących daną sieć; każdy z przełączników powinien być podłączony zgodnie z hierarchią jednym połączeniem do przełącznika nadrzędnego oraz drugim do jego „funkcjonalnego zabezpieczenia”. Analogicznie należy postępować z urządzeniami zduplikowanymi. Tak powstanie w miarę gęsta pajęczyna połączeń urządzeń zduplikowanych, która ma tę podstawową zaletę że każdy z poziomów ma swoje oddzielne zabezpieczenia przez co sieć jako całość odporna jest na awarię więcej niż jednego przełącznika (w przypadku kiedy przełącznik posiadał swoje funkcjonalne zabezpieczenie). Podłączenie serwera do każdej z sieci realizowane jest za pomocą co najmniej dwóch interfejsów podłączonych do dwóch switchy. Aby można było aktywnie korzystać z wdrożonej redundancji na poziomie systemu operacyjnego stosowane są mechanizmy dostępu wielościeżkowego. W Linuksie mechanizmem takim jest Bonding, w Solarisie IPMP, w AIXie VIPA. W przypadku Bondingu czy VIPA tworzony jest dodatkowy wirtualny interfejs który do komunikacji wykorzystuje fizyczne interfejsy podłączone do sieci. Całkowicie odmiennie działa IPMP gdzie każdy z interfejsów fizycznych jest standardowo konfigurowany a następnie za pomocą dedykowanego daemona przełączany jest pomiędzy nimi adres IP usługi definiowany jako alias dla interfejsu fizycznego. W sieciach SAN bazując na podobnej koncepcji zastosowano odmienną implementację.
Na szczęście urządzenia sieciowe LAN czy nawet SAN stają się coraz powszechniejsze, i przez to coraz tańsze, dzięki temu zastosowanie duplikacji infrastruktury nie jest już tak bolesne finansowo jak to kiedyś bywało. Najpopularniejszą obecnie architekturą sieci jest tzw. Core-Edge. Oznacza to budowanie sieci w oparciu o zaawansowane i wydajne główne przełączniki sieciowe, realizujące kierowanie i agregację ruchu z podłączonych sieci. Do nich przyłączone są przełączniki brzegowe do których podłączane są zazwyczaj urządzenia końcowe - serwery, albo połączenia do innych, odległych sieci. Architektura taka tworzy zazwyczaj sieć w postaci drzewa o pojedynczych poziomach odgałęzień. Jak do tej pory opis ten miał zastosowanie zarówno dla sieci LAN jaki i SAN i na tym podobieństwa projektowe tych sieci się kończą. W przypadku sieci LAN duplikacja oznacza dodanie do każdego z poziomów drzewa bliźniaczego urządzenia obsługującego potencjalnie taki sam ruch jak urządzenie zabezpieczane. Każde z tych urządzeń należy odpowiednio podpiąć do pozostałych urządzeń zgodnie z następującym schematem: każde z urządzeń końcowych musi być podłączone do dwóch różnych przełączników brzegowych obsługujących daną sieć; każdy z przełączników powinien być podłączony zgodnie z hierarchią jednym połączeniem do przełącznika nadrzędnego oraz drugim do jego „funkcjonalnego zabezpieczenia”. Analogicznie należy postępować z urządzeniami zduplikowanymi. Tak powstanie w miarę gęsta pajęczyna połączeń urządzeń zduplikowanych, która ma tę podstawową zaletę że każdy z poziomów ma swoje oddzielne zabezpieczenia przez co sieć jako całość odporna jest na awarię więcej niż jednego przełącznika (w przypadku kiedy przełącznik posiadał swoje funkcjonalne zabezpieczenie). Podłączenie serwera do każdej z sieci realizowane jest za pomocą co najmniej dwóch interfejsów podłączonych do dwóch switchy. Aby można było aktywnie korzystać z wdrożonej redundancji na poziomie systemu operacyjnego stosowane są mechanizmy dostępu wielościeżkowego. W Linuksie mechanizmem takim jest Bonding, w Solarisie IPMP, w AIXie VIPA. W przypadku Bondingu czy VIPA tworzony jest dodatkowy wirtualny interfejs który do komunikacji wykorzystuje fizyczne interfejsy podłączone do sieci. Całkowicie odmiennie działa IPMP gdzie każdy z interfejsów fizycznych jest standardowo konfigurowany a następnie za pomocą dedykowanego daemona przełączany jest pomiędzy nimi adres IP usługi definiowany jako alias dla interfejsu fizycznego. W sieciach SAN bazując na podobnej koncepcji zastosowano odmienną implementację. 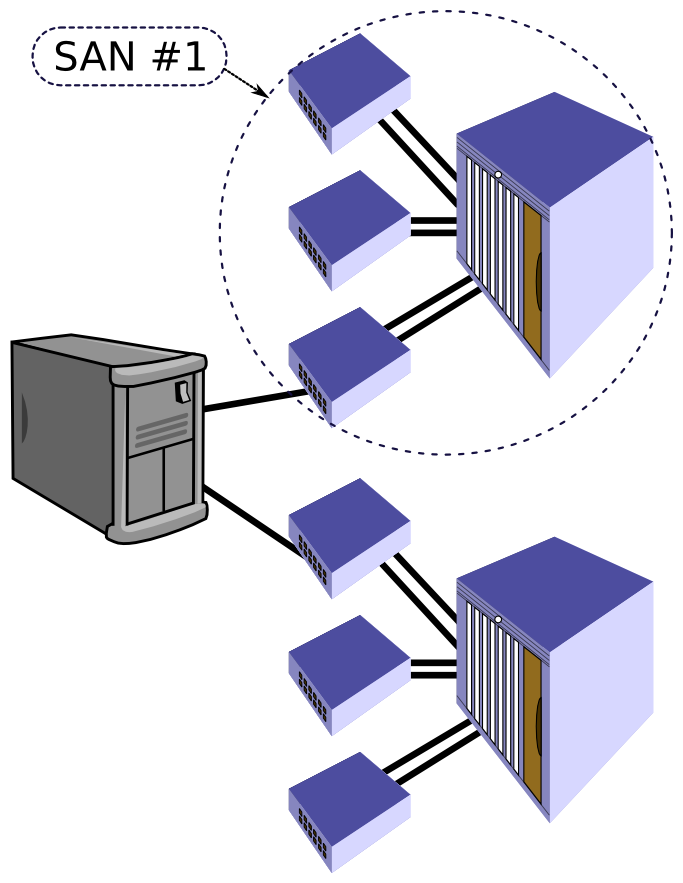 Tutaj także pełnymi garściami korzystamy z duplikacji sieci, lecz tym razem stosując ją bezpośrednio, tworząc w pełni funkcjonalne i całkowicie niezależne od siebie podwojone sieci SAN. Taka implementacja w pełni wpasowuje się w opisywane wcześniej narzędzia dostępu wielościeżkowego do pamięci masowej. Mając już w pełni zduplikowaną infrastrukturę sieci SAN w postaci dwóch niezależnych sieci możemy głębiej zastanowić się nad konsekwencjami takiego wyboru. Podstawową zaletą jest to że jakiekolwiek zawirowania i niedostępności w jednej sieci nie mają wpływu na działanie drugiej sieci, co w przypadku pracy z najpopularniejszym protokołem w sieciach SAN – SCSI, ma niebagatelne znaczenie. Ta zaleta jest jednocześnie wadą ponieważ awaria przełącznika głównego (core) powoduje niedostępność lub podzielenie (osobiście nie wiem co gorsze) całej sieci a co za tym idzie utratę zabezpieczenia w całym środowisku do którego podłączonych może być nawet setki czy tysiące serwerów. Sprawa tym bardziej się komplikuje że sieć SAN jak każde szanujące się obecnie urządzenie znaczną część swojej logiki realizuje za pomocą odpowiedniego oprogramowania – firmware’u, a ten warto by co jakiś czas aktualizować w trakcie planowanych prac. Dobrze by więc było aby takie prace nie powodowały niedostępności całej jednej sieci SAN (kłaniają się metody projektowania systemów Fault Tolerant). Problem rozwiązano poprzez dodatkowe zdublowanie przełączników głównych w ramach każdej z niezależnych sieci SAN. Finalnie mamy więc sytuację taką że sieć SAN jest zdublowana ale ilość przełączników głównych jest nie dwu ale czterokrotnie większa. Aby całość nie wyglądała jak kiepski żart sprzedawcy, zaczęto produkować zdublowane przełączniki SAN w jednej obudowie nazywając je ”Director”.
Tutaj także pełnymi garściami korzystamy z duplikacji sieci, lecz tym razem stosując ją bezpośrednio, tworząc w pełni funkcjonalne i całkowicie niezależne od siebie podwojone sieci SAN. Taka implementacja w pełni wpasowuje się w opisywane wcześniej narzędzia dostępu wielościeżkowego do pamięci masowej. Mając już w pełni zduplikowaną infrastrukturę sieci SAN w postaci dwóch niezależnych sieci możemy głębiej zastanowić się nad konsekwencjami takiego wyboru. Podstawową zaletą jest to że jakiekolwiek zawirowania i niedostępności w jednej sieci nie mają wpływu na działanie drugiej sieci, co w przypadku pracy z najpopularniejszym protokołem w sieciach SAN – SCSI, ma niebagatelne znaczenie. Ta zaleta jest jednocześnie wadą ponieważ awaria przełącznika głównego (core) powoduje niedostępność lub podzielenie (osobiście nie wiem co gorsze) całej sieci a co za tym idzie utratę zabezpieczenia w całym środowisku do którego podłączonych może być nawet setki czy tysiące serwerów. Sprawa tym bardziej się komplikuje że sieć SAN jak każde szanujące się obecnie urządzenie znaczną część swojej logiki realizuje za pomocą odpowiedniego oprogramowania – firmware’u, a ten warto by co jakiś czas aktualizować w trakcie planowanych prac. Dobrze by więc było aby takie prace nie powodowały niedostępności całej jednej sieci SAN (kłaniają się metody projektowania systemów Fault Tolerant). Problem rozwiązano poprzez dodatkowe zdublowanie przełączników głównych w ramach każdej z niezależnych sieci SAN. Finalnie mamy więc sytuację taką że sieć SAN jest zdublowana ale ilość przełączników głównych jest nie dwu ale czterokrotnie większa. Aby całość nie wyglądała jak kiepski żart sprzedawcy, zaczęto produkować zdublowane przełączniki SAN w jednej obudowie nazywając je ”Director”.
Procesory, pamięć, karty IO, czyli o wnętrznościach słowa dwa. . .
Obszar procesorów, pamięci czy podsystemu IO jest obszarem, na który jako administratorzy czy specjaliści wdrażający rozwiązania wysoko-dostępne praktycznie nie mamy żadnego wpływu. Dokładniej to wpływ ten jest bardzo mocno ograniczony poprzez stosowanie określonych architektur sprzętowych, w których ilość procesorów czy kanałów pamięci/IO jest z góry narzucona. Nie bez znaczenia są także możliwości finansowe naszego sponsora. 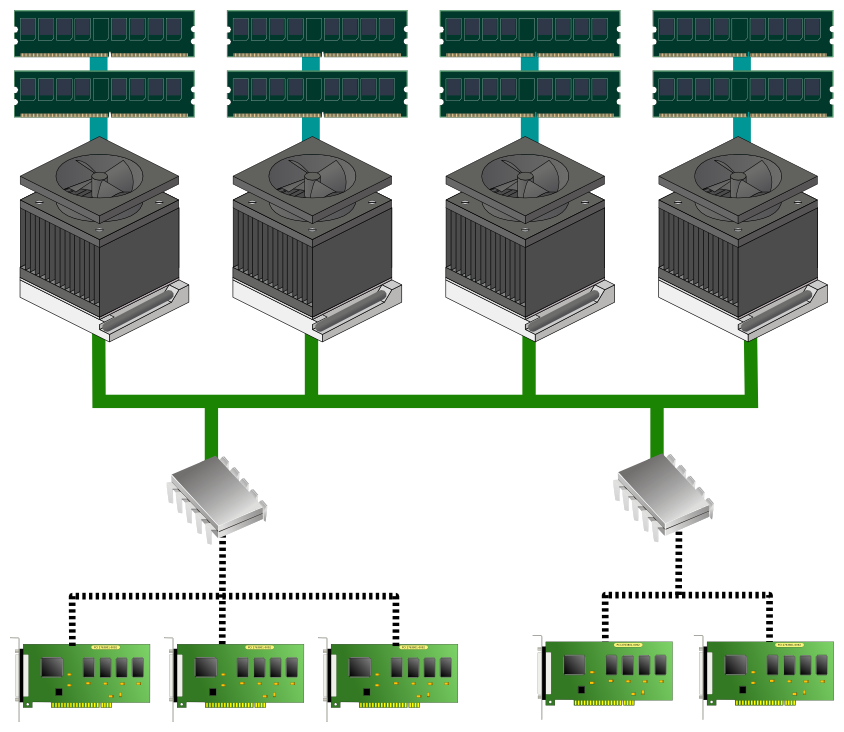 Nie od dziś wiadomo że im sprzęt ma większe możliwości czy mechanizmy niezawodnościowe tym jego cena bardziej szybuje w górę. Jeśli jednak nie jesteśmy ograniczeni w możliwościach wyboru sprzętu to ponownie powinniśmy pamiętać o zasadzie eliminacji SPOF. Tym razem w wydaniu serwerowym zalecenia wyglądają następująco: serwer powinien posiadać o jeden procesor więcej (najlepiej liczony jako socket) niż wymaga aplikacja/usługa – w przypadku uszkodzenia jednego z nich na poziomie testów POST może być on zwyczajnie wyłączony (ang. blacklisting). Ze względu na koszty nie stosuje się mirroringu pamięci RAM za to kości pamięci powinny być obowiązkowo wyposażone w korekcję błędów ECC. Ilość obsadzonych banków pamięci, analogicznie jak w przypadku procesorów, powinna być o jeden większa niż wymaga tego usługa/aplikacja – dzięki temu uszkodzenie pojedynczej kości pamięci wyłączy (dzięki mechanizmowi blacklistingu w procedurach POST) jeden „nadmiarowy” bank pamięci finalnie nie uszczuplając posiadanych zasobów. Pozostaje jeszcze sprawa poprawnego obsadzenia kart IO, szczególnie w przypadku stosowania mechanizmów wielościeżkowości dla dysków czy sieci LAN opisanych wcześniej. W tym przypadku warto zweryfikować czy karty instalowane są na niezależnych magistralach/mostkach PCI dostępnych w serwerze. Dzięki temu problemy z daną magistralą czy mostkiem PCI nie powinny wpłynąć na dostępność naszej usługi. Oczywiście nie każda architektura czy nawet klasa sprzętu ma opisane tu możliwości, tak więc podczas wyboru możemy traktować to jako jedno z kryteriów
Nie od dziś wiadomo że im sprzęt ma większe możliwości czy mechanizmy niezawodnościowe tym jego cena bardziej szybuje w górę. Jeśli jednak nie jesteśmy ograniczeni w możliwościach wyboru sprzętu to ponownie powinniśmy pamiętać o zasadzie eliminacji SPOF. Tym razem w wydaniu serwerowym zalecenia wyglądają następująco: serwer powinien posiadać o jeden procesor więcej (najlepiej liczony jako socket) niż wymaga aplikacja/usługa – w przypadku uszkodzenia jednego z nich na poziomie testów POST może być on zwyczajnie wyłączony (ang. blacklisting). Ze względu na koszty nie stosuje się mirroringu pamięci RAM za to kości pamięci powinny być obowiązkowo wyposażone w korekcję błędów ECC. Ilość obsadzonych banków pamięci, analogicznie jak w przypadku procesorów, powinna być o jeden większa niż wymaga tego usługa/aplikacja – dzięki temu uszkodzenie pojedynczej kości pamięci wyłączy (dzięki mechanizmowi blacklistingu w procedurach POST) jeden „nadmiarowy” bank pamięci finalnie nie uszczuplając posiadanych zasobów. Pozostaje jeszcze sprawa poprawnego obsadzenia kart IO, szczególnie w przypadku stosowania mechanizmów wielościeżkowości dla dysków czy sieci LAN opisanych wcześniej. W tym przypadku warto zweryfikować czy karty instalowane są na niezależnych magistralach/mostkach PCI dostępnych w serwerze. Dzięki temu problemy z daną magistralą czy mostkiem PCI nie powinny wpłynąć na dostępność naszej usługi. Oczywiście nie każda architektura czy nawet klasa sprzętu ma opisane tu możliwości, tak więc podczas wyboru możemy traktować to jako jedno z kryteriów
porównawczych.
Serwery, klastry, farmy i inne zwierzęta. . .
Gdy pozabezpieczamy już niższe warstwy infrastruktury: zasilanie, pamięć masową, sieci LAN oraz SAN to w końcu przychodzi czas na zajęcie się sprawami wyższych warstw, czyli serwery i aplikacje. W warstwach tych sprawa trochę się niestety komplikuje. Wprawdzie w dalszym ciągu powinniśmy projektować środowisko zgodnie z zasadą eliminacji SPOF, lecz spoglądając od strony usługi/aplikacji, a nie samej warstwy. 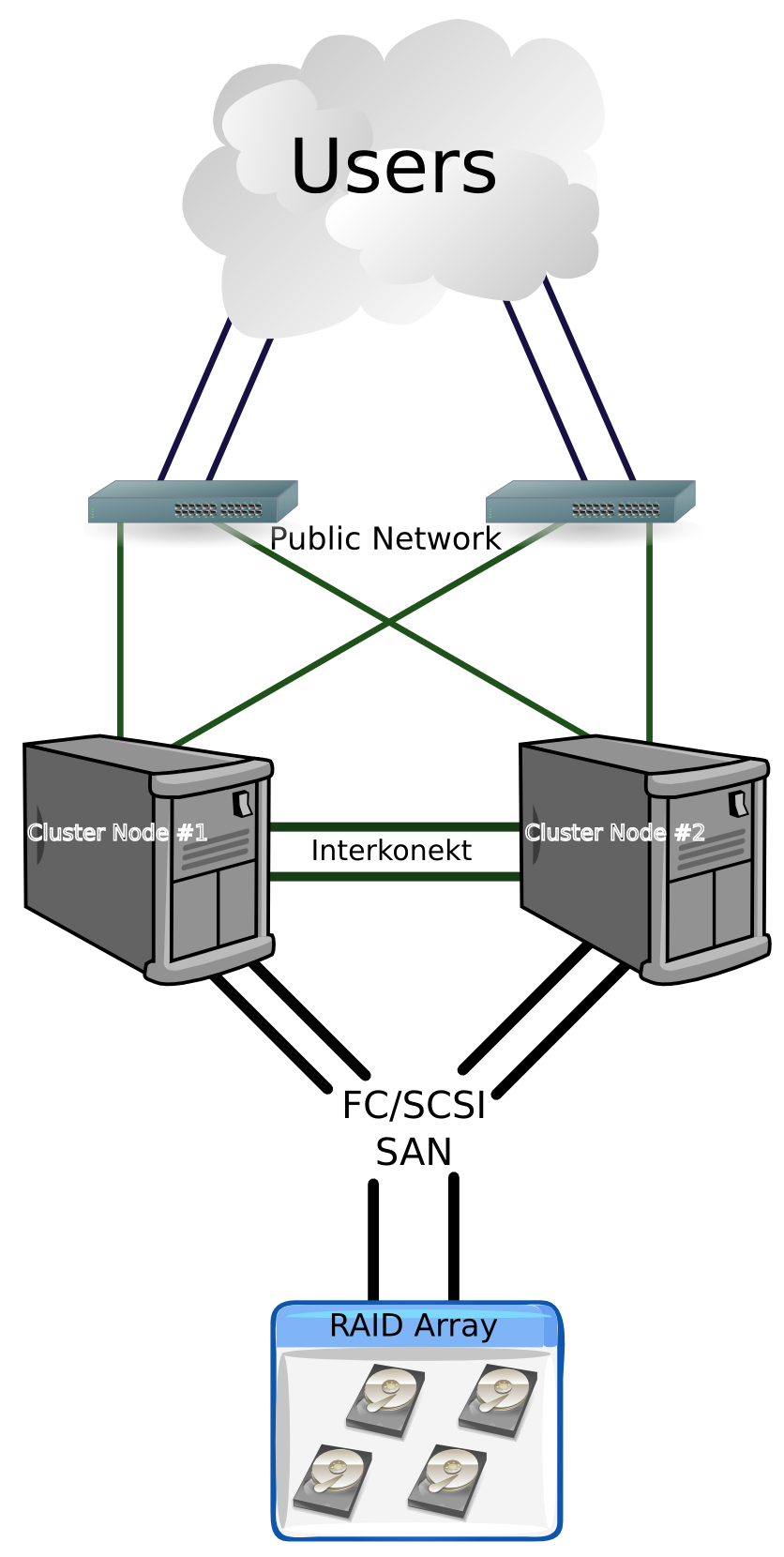 Po pierwsze warstwy systemu operacyjnego i serwera fizycznego nie mogą być rozdzielane (zastosowane wirtualizacji zmienia to założenie), po drugie jeśli przeanalizuje się funkcjonalność wielu usług/aplikacji to nagle może okazać się że wszystko co do tej pory robiliśmy jest całkowicie (albo prawie) niepotrzebne i tylko sztucznie zwiększa koszty związane z wdrożeniem infrastruktury. Ale dlaczego? Postaram się to wytłumaczyć. Tak więc do dyspozycji mamy dwa a dokładniej trzy rodzaje technik zabezpieczania: klastry systemowe, farmy balansowane oraz klastry aplikacyjne. Z punktu widzenia infrastruktury zarówno farmy jak i klastry aplikacyjne są do siebie bardzo podobne i często traktowane jako wspólny obszar. Klastry to grupa komputerów świadczących określone usługi zbudowana w taki sposób, że nawzajem dublują swoje funkcje. Farmy czy klastry aplikacyjne to grupa komputerów świadczących określone usługi, zbudowane w taki sposób że wszystkie komputery jednocześnie świadczą tą sama usługę ale dla innego klienta czy transakcji. Podstawowa różnica pomiędzy farmą a klastrem aplikacyjnym jest w poziomie „świadomości” samej aplikacji w świadczeniu usługi wysoko-dostępnej. W terminologii klastrowej występuje szereg specyficznych dla tego gatunku informatyki pojęć, m.in:
Po pierwsze warstwy systemu operacyjnego i serwera fizycznego nie mogą być rozdzielane (zastosowane wirtualizacji zmienia to założenie), po drugie jeśli przeanalizuje się funkcjonalność wielu usług/aplikacji to nagle może okazać się że wszystko co do tej pory robiliśmy jest całkowicie (albo prawie) niepotrzebne i tylko sztucznie zwiększa koszty związane z wdrożeniem infrastruktury. Ale dlaczego? Postaram się to wytłumaczyć. Tak więc do dyspozycji mamy dwa a dokładniej trzy rodzaje technik zabezpieczania: klastry systemowe, farmy balansowane oraz klastry aplikacyjne. Z punktu widzenia infrastruktury zarówno farmy jak i klastry aplikacyjne są do siebie bardzo podobne i często traktowane jako wspólny obszar. Klastry to grupa komputerów świadczących określone usługi zbudowana w taki sposób, że nawzajem dublują swoje funkcje. Farmy czy klastry aplikacyjne to grupa komputerów świadczących określone usługi, zbudowane w taki sposób że wszystkie komputery jednocześnie świadczą tą sama usługę ale dla innego klienta czy transakcji. Podstawowa różnica pomiędzy farmą a klastrem aplikacyjnym jest w poziomie „świadomości” samej aplikacji w świadczeniu usługi wysoko-dostępnej. W terminologii klastrowej występuje szereg specyficznych dla tego gatunku informatyki pojęć, m.in:
- węzeł klastra – komputer wchodzący w skład infrastruktury klastra;
- interkonekt klastrowy – bezpośrednie połączenie węzłów klastra służące wymianie informacji potrzebnych do poprawnego działania klastra;
- heartbeat – zbiór metod odpowiedzialnych za weryfikację poprawności działania środowiska klastrowego;
- splitbrain – stan w którym każdy z węzłów (lub pewna część) klastra utracił wiarygodną informację o statusie działania/dostępności pozostałych węzłów klastra (sytuacja występuje zazwyczaj w przypadku utraty kanału komunikacyjnego dla heartbeat’u);
- quorum – obiekt/zasób krytyczny o współdzielonym dostępie z węzłów klastra umożliwiający osiągnięcie większości w trakcie elekcji w sytuacji splitbrain;
- elekcja – działanie mające na celu wyłonienie wyłącznie jednego reprezentanta mającego świadczyć daną usługę w przypadku wystąpienia sytuacji splitbrain lub innej awarii;
- fencing – mechanizm mający na celu odizolowanie od infrastruktury współdzielonej węzła klastra w przypadku wystąpienia sytuacji splitbrain lub innej awarii tego węzła;
- usługa klastrowa – zbiór zasobów wymaganych do poprawnej pracy usługi informatycznej lub aplikacji, zasoby mogą być dostarczane explicite poprzez odpowiednią konfigurację klastra (np. zasoby dyskowe, adresy IP, dane) lub są zasobami domyślnymi (np. procesor, pamięć ram, itp.);
- współdzielone zasoby dyskowe – pamięć masowa występująca jako jeden z zasobów usługi klastrowej dzięki której możliwe jest uruchomienie usługi na różnych węzłach klastra w takim samym środowisku uruchomieniowym, z tymi samymi danymi;
- usługa balansowana – usługa informatyczna lub aplikacja działająca na farmie balansowanej skonfigurowana w taki sposób aby od strony klienta była widoczna tak jakby pracowała na pojedynczym serwerze;
- RIP – „Real IP” – adres usługi działającej na serwerach farmy, zazwyczaj nie biorący udziału w bezpośredniej komunikacji klienta z usługą;
- VIP – „Virtual IP” adres wirtualny usługi balansowanej;
- balansowanie obciążenia – metody/strategie przekierowywania ruchu sieciowego związanego z usługa balansowaną w taki sposób aby zapewnić równomierne obciążenie serwerów farmy (skalowanie poziome wydajności usługi).
Klaster aplikacyjny, jak już to zostało wcześniej wspomniane, od strony infrastruktury jest łudząco podobny do farmy, w rzeczywistości jest odmianą farmy z mechanizmami balansowania obciążenia czy zapewnienia wysokiej-dostępności obsługiwanymi całkowicie po stronie aplikacji (w większym lub mniejszym stopniu). Dla przykładu balansowanie obciążenia może być realizowane za pomocą mechanizmów przekazywania zadań do wykonania w obrębie klastra czy pobierania zadań do wykonania z „centralnego” repozytorium zadań. Mechanizmy wysoko-dostępne mogą być realizowane poprzez cykliczne odwoływanie się klientów usługi do kolejnych zdefiniowanych adresów serwerów klastra – w ten sposób można także realizować jedną ze strategii balansowania obciążenia w przypadku obsługi jednoczesnej wielu klientów czy transakcji/żądań – czy poprzez odpytywanie serwerów/usługi monitorującej dostępność serwerów klastra. Jako że obszar ten dotyczy samej istoty rzeczy/funkcjonalności usługi, to każda implementacja jest specyficzna dla danej usługi i bardzo trudno opisywać tu każdy z możliwych scenariuszy, w końcu każdy projektant aplikacji może sobie wymyślić nowy. Wróćmy więc do klastrów systemowych i farm balansowanych. Podstawowym kryterium w wyborze jednej z dwóch możliwości jest charakter działania usługi/aplikacji. W przypadku usług, które w naturalny sposób mogą być skalowane w poziomie, czyli wszystkich usług silnie wielowątkowych i słabo zależnych od wspólnych danych lub nie wymagających transakcyjności w dostępie do tych danych, jedynym sensownym rozwiązaniem jest farma balansowana. Na skrajnym biegunie funkcjonalnym mamy aplikacje silnie transakcyjne, silnie zależne od dostępu do wspólnych danych czy wręcz o ograniczonej wielowątkowości. Wszystkie te rodzaje aplikacji ze względów czysto technicznych umieszcza się na klastrach systemowych. Klastry takie z punktu widzenia działającej aplikacji zachowują się jak pojedynczy serwer, który w razie awarii jest automatycznie podmieniany na inny działający w klastrze. Jako że „podmiana” ta jest realizowana automatycznie, więc drugi węzeł musi cały czas działać i w najprostszym przypadku oczekiwać na przejęcie usługi. Z tego powodu aplikacja działająca w środowisku klastrowym musi być tak zaprojektowana i skonfigurowana, aby podmiana serwera posiadającego unikalne cechy takie jak: hostname, hostid, prywatne adresy IP itp., była dla tej aplikacji całkowicie obojętna i przeźroczysta. Niestety nie wszystkie aplikacje spełniają te wymagania. W takim wypadku z pomocą przychodzi nam wirtualizacja i uruchomienie wirtualnego hosta jako usługi klastrowej. Wymienione wcześniej unikalne cechy każdego z węzłów klastra nie mają tu zastosowania, środowisko wirtualne zawsze jest takie same bez względu na to na jakim węźle klastra obecnie usługa pracuje.
Koszty, czyli wąż w kieszeni wcale nie musi być jadowity. . .
Pierwszym i podstawowym pytaniem jakie zadają sobie szefowie działów IT w dużych czy małych firmach jest: Ile rozwiązania wysoko dostępne kosztują? Faktem jest, iż kosztują więcej niż środowiska całkowicie bez zabezpieczeń. Czasami kosztują aż dwukrotnie więcej, czasami nawet trzykrotnie więcej, czasami mniej, ta granica jest bardzo płynna. Aby precyzyjnie odpowiedzieć na pytanie czy firmie się to po prostu opłaca należałoby dla każdego konkretnego przypadku wykonać szczegółową analizę w ramach analizy ryzyka operacyjnego istniejącego w firmie. Temat zarządzania ryzykiem znacznie wykracza poza ramy tego referatu w związku z czym skupimy się na bardzo ogólnej charakterystyce wymagań. Dla najprostszego przypadku potrzebować będziemy kilku danych, w tym kosztów jakie firma ponosi z tytułu przestoju/niedziałania usługi, wariantów kosztów związanych z różnymi poziomami zabezpieczeń jakie jesteśmy w stanie wdrożyć (może także w powiązaniu z prawdopodobieństwem wystąpienia różnych awarii przed którymi będziemy się zabezpieczać). Warto by także zorientować się jak wygląda sprawa z przeniesieniem odpowiedzialności/ryzyka związanego z awarią na podmiot trzeci, czyli po naszemu: ile kosztuje serwis. Teraz stosując kolejne uproszczenie analizy porównujemy koszt wdrożenia zabezpieczeń czy serwisu względem strat jakie poniesie firma, jeśliby tych zabezpieczeń nie wdrożyła, w zakładanym okresie czasu. Dla bardziej dokładnych proponuję pobawić się w analizę z wykorzystaniem prawdopodobieństwa awarii wyliczonego z deklarowanych przez producentów MTBF (ang. Mean Time Between Failure) dla każdego z analizowanych komponentów. Projektując naszą wysoko-dostępną infrastrukturę musimy pamiętać o następujących uwarunkowaniach: koszt zabezpieczenia usługi w przypadku farm balansowanych maleje wraz ze wzrostem ilości serwerów – poziom zabezpieczenia N+1. Dodatkowo przy przekroczeniu pewnej liczby serwerów w farmie (z doświadczenia powyżej 10) każdy z serwerów może być traktowany jako pojedyncza jednostka obliczeniowa która zapewnia redundancję jako całość, w związku z czym stosowanie dodatkowych zabezpieczeń w ramach takiego serwera nie jest uzasadnione. Mniejszym kosztem jesteśmy w stanie dostarczyć dodatkowy serwer niż ponosić wydatki związane z zabezpieczeniem poszczególnych warstw infrastruktury. W tym wypadku nawet niewielkie oszczędności na pojedynczym serwerze należy przemnożyć w skali całej farmy. Z tego też powodu w takich warunkach najczęściej stosowane są serwery blade, zwane też kasetowymi. Serwery takie praktycznie nie mają możliwości rozbudowy, a ilość dostępnych portów sieciowych czy kart IO spełnia minimalne akceptowalne wielkości. Całkowicie inaczej sprawa wygląda w przypadku klastrów systemowych, tutaj przy klasycznym podejściu projektowym koszt zabezpieczenia pojedynczej usługi może spokojnie przekroczyć dwukrotność kosztów środowiska bez zabezpieczeń. Taka architektura klastra opisywana jest jako active-standby i zazwyczaj zapewnia maksymalny poziom świadczenia usługi, nie tylko ze względu na dostępność ale także ze względu na wydajność – drugi węzeł klastra w pełnej gotowości zwyczajnie czeka na jakieś problemy z głównym węzłem. W tym przypadku do pomocy przychodzą nam alternatywne możliwości wykorzystania klastra opisywane jako active-active czy wręcz architektura opisywana jako N+1. Opcje takie są interesujące z kilku powodów: jak pokazują statystyki średnie obciążenie serwerów UNIX waha się w okolicach 20%, w przypadku budowania kilku środowisk dla usług wysoko-dostępnych w klasycznym podejściu otrzymamy sporą ilość sprzętu oczekującego na awarię i generującego koszty zamiast zarobku, dodatkowo koszty administrowania klastra z jedną usługą klastrową są praktycznie takie same jak klastra z kilkoma usługami klastrowymi. Stąd już bardzo blisko do wniosku, że zbudowanie klastra dla co najmniej dwóch usług klastrowych jest znacznie bardziej opłacalne niż budowanie dwóch oddzielnych środowisk klastrowych. Oczywiście dodatkowym kosztem w tym przypadku będzie potencjalne obniżenie wydajności usług klastrowych w przypadku wystąpienia awarii kiedy obie usługi będą okupowały jeden serwer. Z drugiej strony taka sytuacja nie powinna się zbyt często zdarzać więc potencjalne zyski powinny być spore (a jakie to powinniśmy wyliczyć w ramach wspomnianej analizy ryzyka operacyjnego). Jeśli jednak spadek wydajności w trakcie awarii jest nie do zaakceptowania to można pokusić się o wdrożenie klastra w architekturze N+1, czyli N serwerów aktywnych + 1 serwer standby. Dzięki temu koszt zbudowania takiego środowiska dla co najmniej dwóch usług klastrowych powinien być mniejszy niż w klasycznym podejściu, choć wyższy niż w przypadku active-active. Dzięki temu jeśli zdarzy się awaria jednego dowolnego węzła aktywnego to usługa klastrowa na nim działająca będzie w stanie ze 100% wydajnością pracować na jednym zapasowym serwerze. Architektura ta ma także wady: przełączenie dwóch usług klastrowych w jednym czasie na serwer zapasowy oznacza degradację wydajności tych usług, utrudnione jest także administrowanie takim klastrem, szczególnie kiedy ilość aktywnych węzłów klastra będzie większa. Posiada ona także niewidoczne na pierwszy rzut oka zalety: daje możliwość elastycznej rozbudowy mocy obliczeniowej klastra, gdzie rozbudowie podlegają wyłącznie: jeden węzeł aktywny klastra oraz węzeł zapasowy tylko w przypadku kiedy ma on niewystarczającą moc obliczeniową. W przypadku klastrów active-standby czy active-active rozbudowa musi być wykonana zawsze dla dwóch węzłów jednocześnie.
Wyższy poziom wtajemniczenia, czyli Disaster Recovery. . .
„I nadeszły te czasy kiedy usługi i aplikacje były ciągle dostępne. I pracowały bez wytchnienia dla dobra firm wszelakich. Aż nastał czas próby kiedy to jedyna serwerownia katastrofą została dotknięta i zastanowił się administrator czy aby nic już się nie dało zrobić?” – Ale o tym opowiemy już w następnym odcinku.